
Databases need no introduction.
They can be as simple as an IndexDB inside your browser or as robust as a managed PostgreSQL, but most apps we build use some relational database.
However, as our data becomes more connected and complex, gaining meaningful insights becomes more difficult.
In this post, you will learn:
What are graph databases, and why are they different from relational databases?
How to do migrations?
How to query them?
Why it matters
The future of data lies in the connections we make.
For the past few weeks, I have researched how we can gain insights from billions of interconnected data points.
During this research, I learned that ISO published a new database query language: ISO GQL.
So why is this a big deal?
It’s the first new ISO database language since 1987.
So I thought, if something, then this is worth writing about.
Disclaimer: I do this as someone who has never worked with graph databases before, which is where AI tools were of incredible help in learning fast. I wrote about this here:

Every. Single Database.
Data is stored in tables.
Tables are connected with foreign keys, which is how relations are created – at least as far as traditional relational databases go.

Then your data is stored like this in the books table
id | title | published_year | author_id
1 | OpenAI Cookbook | 2024 | 1
and in the authors table:
id | name | birthday
1 | Akos | 1988-01-01
You get two things from neatly storing data this way: organization and rigidness. And while having a straightforward schema you can follow is good for many reasons, let’s be honest, we’ve all gotten requests like:
Show me all the books that this author published between 2020 and 2024 and find every other book that was published on the same date, in the same category, and got the same number of reviews within the first 20 hours of publishing.
And you’d be like

We didn’t store when the books were published. We don’t have categories or reviews.
As you discover new use cases, the schema you started with, at some point, is an entirely different schema.
Changes like this usually involve migrations, backfills, and tears.
What if your data model could evolve as your application grows, and you could gain insights without formally introducing new columns or doing migrations?
What Are Graph Databases?
In graph databases, data is stored in a graph.
Nodes represent entities, like authors or books.
Edges represent relationships between these entities.
Both nodes and edges can have properties.
We also have labels to categorize nodes.
So instead of focusing on putting the data into well though-out tables, such as the authors table and the books table, we say:
Let there be books and authors. And let authors publish books.

The Cost of Change
As software constantly evolves, the schema is destined to change.
Let’s say the business wants you to implement coauthors.
Coauthors are also authors but can appear for books next to the author. One book can have many coauthors.
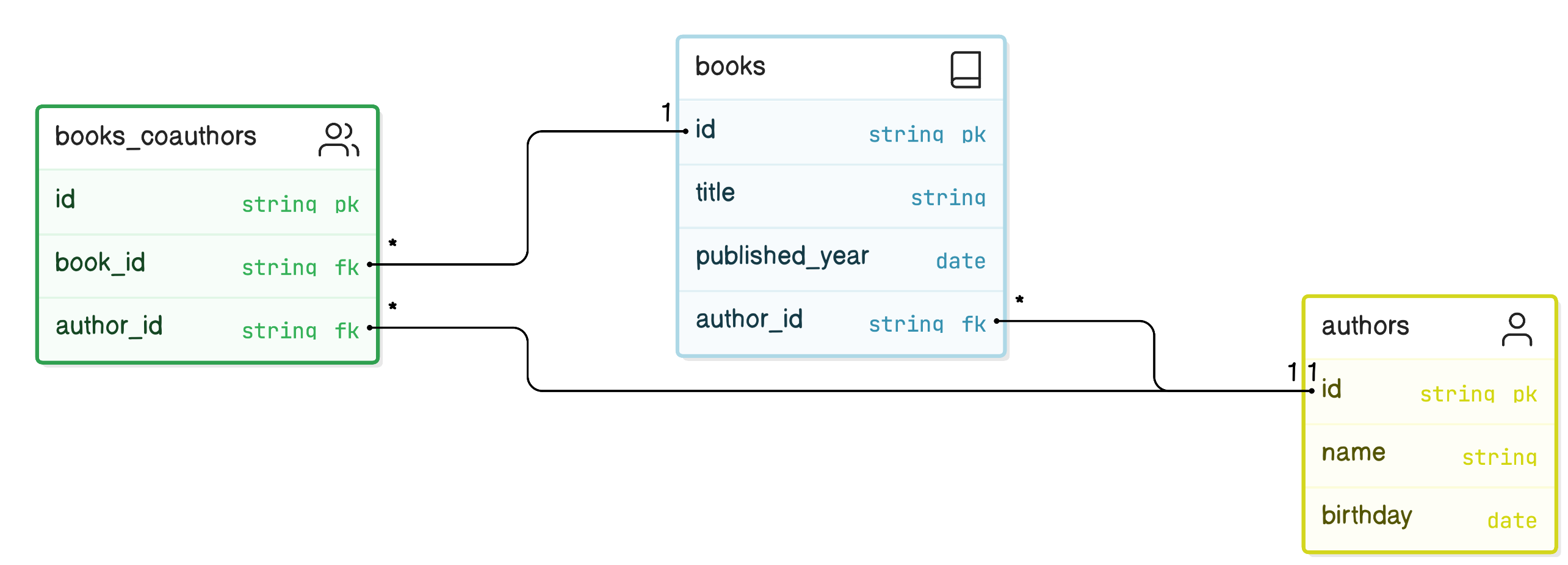
In the RDB world, this means at least one migration, inside which you add the extra table and two new constraints.
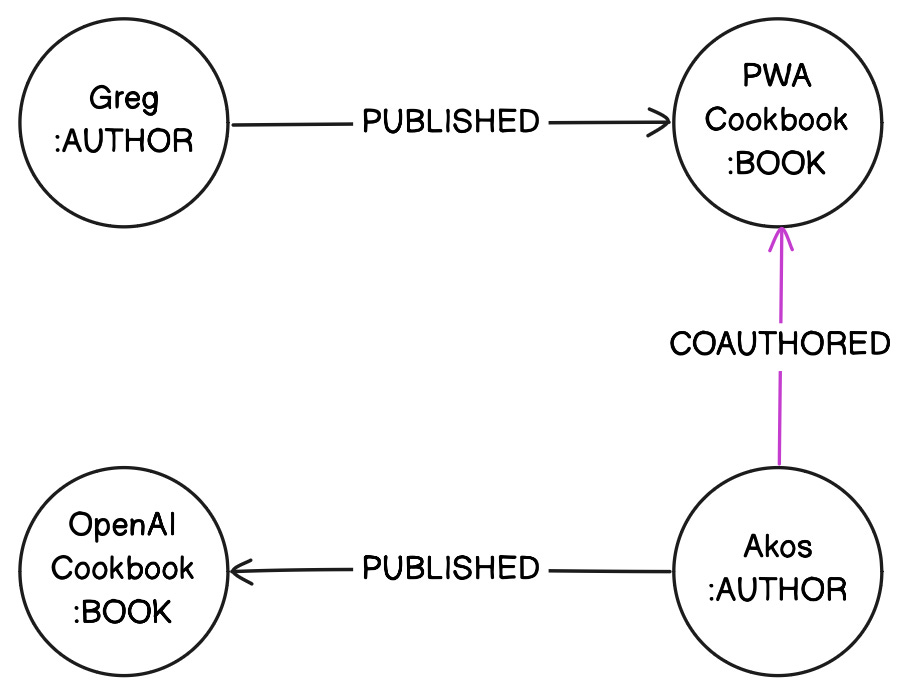
In the graph database world, being a coauthor is really just a new type of relation:
SQL for Graph Databases
As I mentioned at the beginning, GQL (not to be confused with GraphQL, a totally different technology) is one way to query graph databases. There are more tools, but more on that in the next newsletters.
The syntax is SQL-like.
To find all coauthors for a book called OpenAI Cookbook, you would do something like this in PostgreSQL:
SELECT a.name
FROM books b
JOIN books_coauthors bc ON b.id = bc.book_id
JOIN authors a ON bc.author_id = a.id
WHERE b.book_name = 'OpenAI Cookbook';In GQL - it looks like this:
MATCH (book:Book {name: 'OpenAI Cookbook'})<-[:COAUTHORED]-(coauthor:Author)
RETURN coauthor.nameYou notice the unusual structure with the arrows: ← [] -. This is how you describe relations in the queries, meaning that node A is connected to node B through the relation REL.
(A) <- [:REL] - (B)The direction of the relation is important, and you can use all kinds of quantifiers to find, for example, A and B with 1 to 3 relations between them:
(A) <- [*1..3] - (B)These are the queries where GQL really shines.
This was your short intro to Graph Databases. If you liked it, please like the post and share it with others. 😊
Have you heard about databases or used them before?
📰 Weekly shoutout
📣 Share
There’s no easier way to help this newsletter grow than by sharing it with the world. If you liked it, found something helpful, or you know someone who knows someone to whom this could be helpful, share it:
🏆 Subscribe
Actually, there’s one easier thing you can do to grow and help grow: subscribe to this newsletter. I’ll keep putting in the work and distilling what I learn/learned as a software engineer/consultant. Simply sign up here:
Superb introduction to Graph DBs, Akos!
Haven't worked much with them before and mostly from a distance that they were already used in some corner of the project. This post makes me interested in learning more about them.
Also, thanks for the mention!
graph databases are two types of RDF and priority graph,
they are no standard graph standard language like Ansi SQL, it will be Cypher in neo4j, amazon Neptune, Arango dB ,Apache gremlin, and tighergraph
these used in product recommendations, fraud detection and pattern matching